Compound Routine
Big whirls have little whirls that feed on their velocity, and little whirls have lesser whirls and so on to viscosity.
Much of my work as a data scientist revolves around building systems. It’s one thing to write code to accomplish a task once. It’s another to write code intended to accomplish that task every day. This kind of system building requires a different mentality. For each system, there needs to be a way to maintain it and check to see if it’s working.
When beginning a new project, I’m amazed how quickly these small systems start to compound. From nothing arise multiple systems, one that accomplishes a task, another to check if that task is running every day, another to check if the output of that task matches expectations and so on.
In a similar way, I’m amazed how quickly little systems in my own life start to compound. These procedures arise wherever repetition is present in day to day life—making coffee, exercising, going to work.
I stumbled across a good question recently: “What is it you do to train that is comparable to a pianist practicing scales?” To me, this is basically another way to ask “what systems do you have in place to work every day towards long-term goals?”
Spaced Repetition
I don’t claim to be any better than the average person at systematized practice. I experimented many times with detailed logs of progress toward certain goals (be it improvement on the trumpet, working on personal projects, translating complicated texts to English). However, I always end up abandoning them as they become overcomplicated and burdensome to maintain.
However, I have stumbled across a few good practice techniques. One of them involves improving memory and recall. For me, an excellent way to improve one’s knowledge is through memorization. I’m not interested in cultivating an appearance of being smart or in the challenge of performing feats of memory. I just find it practical to memorize certain facts, such as the speed of light or the conversion between miles and kilometers.
A useful way to do this is to use spaced repetition. One of the best write-ups of spaced repetition is this piece by Gwern. The main premise is that you can improve your recall of information if you are “reminded to remember” the information at spaced intervals. The phenomenon also explains why cramming helps retain information only in the short but not in the long term. One of the neatest mathematical representations of the forgetting curve, proposed by the authors of this clever paper, is this exponential curve:
R = e^(-t/s)
where:
Ris retrievability (the probability of retrieving a learned piece of information at a given moment),
sis stability of memory (the rate at which retrievability declines as a result of forgetting),
tis time.
The idea behind spaced repetition is that our own values of S increase as we are repeatedly prompted to recall the piece of information. Fitting a few values of S to this equation yields a few different forgetting curves:
library("ggplot2")
library("patchwork")
all_plots = list()
all_s = c(1/2,1,3,5)
colors = c("firebrick", "blue", "orange", "purple")
for(curr_s in 1:length(all_s)){
s = all_s[curr_s]
all_R = c()
all_T = c()
for(t in 1:10){
R = exp((-t)/s) ##exponential curve defined here: {R=e^(-t/s)}
all_R = c(all_R, R)
all_T = c(all_T, t)
}
df = data.frame(
t = all_T,
r = all_R
)
plot = ggplot(df, aes(x=t, y=r)) +
geom_line(color = colors[curr_s]) +
geom_point() +
xlab("Time") +
ylab("Retrievability") +
labs(title=paste("Forgetting Curve for Memory Stability Value:", s, sep = " ")) +
theme(plot.title = element_text(hjust = 0.5))
all_plots[[curr_s]] = plot
}
(all_plots[[1]]+all_plots[[2]])/
(all_plots[[3]]+all_plots[[4]])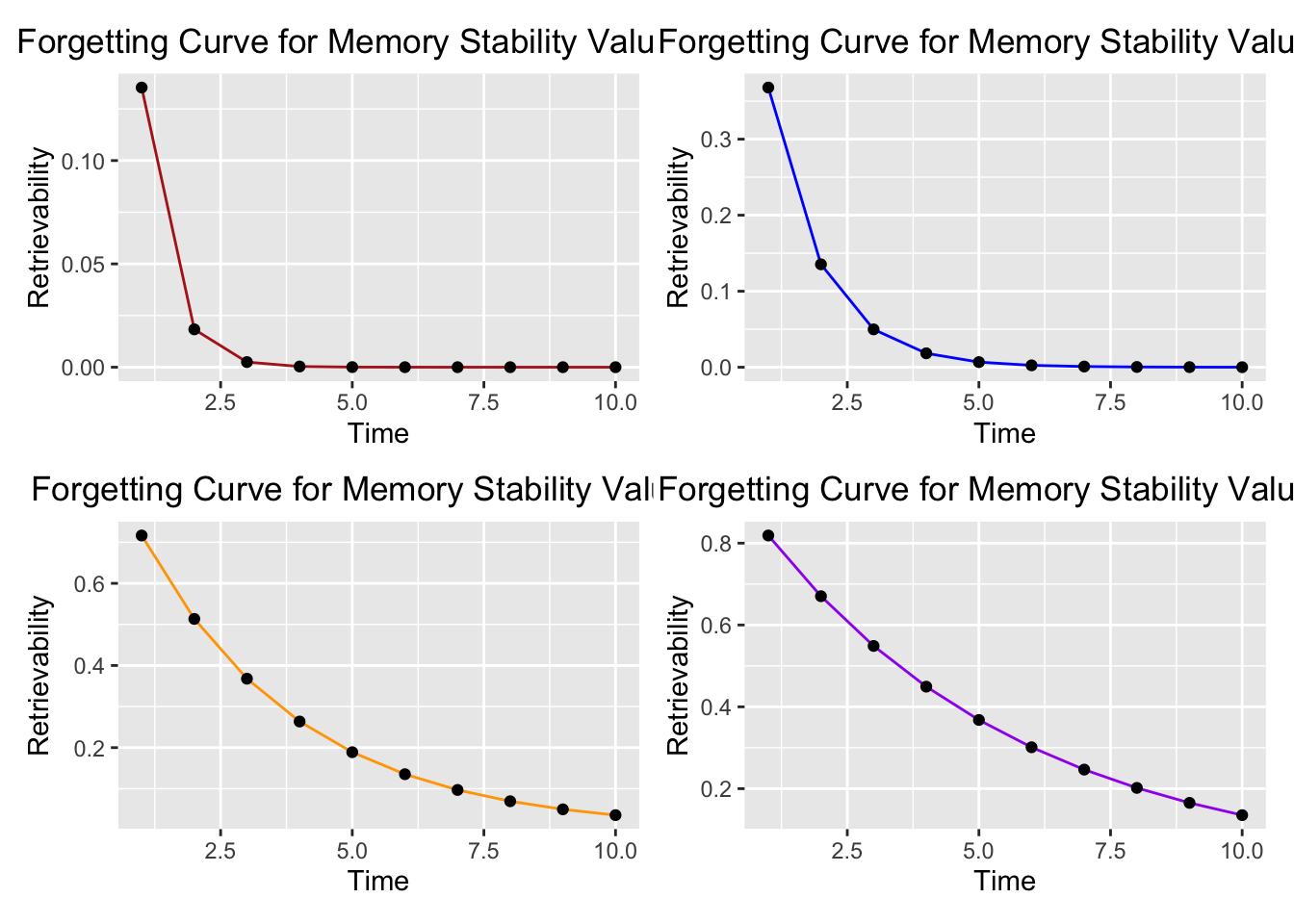
We see that once we are reminded on a regular basis and our ability to recall the information stabilizes, the rate at which we forget the piece of information begins to flatten.
A perfect use for spaced repetition is language learning. While nothing can replace actual conversation for language learning, there is a significant amount of memorization needed to achieve a critical mass of vocabulary in a language to be able to communicate effectively.
There are a whole host applications that aid in spaced repetition. A time-proven favorite, and my personal favorite, is Anki. It’s a free flashcard system that uses the principles of spaced repetition to prompt you to recall pieces of information you want to memorize right before you forget them. It is simple and easy to use but also infinitely customizable. It provides some interesting insights into spaced repetition as well:
Anki Statistics 
Anki-Update System
Overview
While creating flashcards in Anki is easy, manually creating a bunch of them at once is burdensome. I often find that if I need to create too many at one time I simply won’t spare the effort.
To help offset my laziness, I took an hour to design a small system to take words that I want to learn from Google Translate and create flashcards for them. I created a small command line app in Python to automate the effort.
Here are the full steps in the system:
1) I use Google Translate to translate a word, and then star it if I want to memorize it
2) Occasionally, I will click the "Export to Googlesheet" button which will save a spreadsheet with all these starred words to my google drive
3) I will run the python script which automatically does the following:
a. Gathers the most recent Saved Translations file from my drive
b. Cleans the spreadsheet, removes duplicates, and saves separate csv files for separate languages locally on my computer
c. Uploads the clean csv back to my google drive
4) I upload the csvs for each language deck in Anki, which automatically creates the flashcards for meThis saves me a great deal of time and makes me more likely to create new flashcards from the words that I stumble across every day.
I also have an extra step for Russian language. As I’ve written before, Russian words are hard for me because I do not know where the stress falls. Instead of looking up how to pronounce each word and recording the pronunciation in a flashcard (which is possible in Anki), I instead take each word and scrape it’s “Rooglish” pronunciation as well as stress marks from this useful little site here.
For example, take the phrase "главный герой" (main character). By plugging it into the site above, it creates stress marks — so it becomes "гла́вный геро́й". The site goes even further and gives me the “Rooglish” version, or the way the phrase would be pronounced if it were English. In this case, it returns "GLAHV-niy ghe-ROY" so that there is no ambiguity about the pronunciation.
Below, I will outline how each step looks in practice.
Specifics
1) Starring in Google Translate
In Google Translate, I simply click on the star to show what words I’ve saved and want to memorize.
2) Exporting the Starred File
I then click on “Export to Google Sheets”, and it gives me the option to import the data

The sheet then saves automatically to my google drive.

3) Running the Script
I then run this script in terminal. I’ll put the code below, but it’s also available for download in the public repo for this site.
It takes only a few arguments:
export_path– a folder where I want to keep the resulting filesrussian_stress– an optional flag to retrieve the stress marks for Russian wordsrooglish– an optional flag to retrieve the “Rooglish” pronunciation of Russian words
To make it work properly, I need to run the script in the same directory where my client_secrets.json credentials are to access the Google Drive API. This tutorial clearly outlines how to do this.
The command looks like this:
python anki_languages.py --export_path '~/Desktop/anki_import/' --russian_stress --rooglishAnd here is the code:
import click
import sys
import time
from copy import deepcopy
import pandas as pd
from selenium import webdriver
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
def get_stress_marks(phrase, driver, rooglish):
inputElement = driver.find_element_by_id("MainContent_UserSentenceTextbox")
inputElement.send_keys(phrase)
driver.find_element_by_id("MainContent_SubmitButton").click()
time.sleep(3)
inputElement = driver.find_element_by_id("MainContent_UserSentenceTextbox")
stressed_phrase = inputElement.text
if rooglish:
soundElements = driver.find_elements_by_class_name("sounds-like")
sounds_like = ''
for elem in soundElements:
sounds_like = sounds_like + ' ' + elem.text
sounds_like = sounds_like.lstrip()
if stressed_phrase != sounds_like:
stressed_phrase = stressed_phrase + ' (' + sounds_like + ')'
inputElement.clear()
return(stressed_phrase)
def clean_df(df):
df.drop_duplicates(['from_trans'], keep= 'first', inplace = True)
df.drop_duplicates(['to_trans'], keep= 'first', inplace = True)
df = df[df['to_trans']!=df['from_trans']]
return(df)
@click.command()
@click.option('export_path', '--export_path', required = True, help = "Path to folder where upload files should be saved.")
@click.option('russian_stress', '--russian_stress', is_flag = True, help = "Boolean flag to scrape pronunciation symbols.")
@click.option('rooglish', '--rooglish', is_flag = True, help = "Boolean flag to get rooglish pronunciation.")
def create_anki_uploads(export_path, russian_stress, rooglish):
assert export_path.endswith('/')
## Authenticate (note: client_secrets.json need to be in the same directory as the script)
gauth = GoogleAuth()
gauth.LoadCredentialsFile("mycreds.txt") # Try to load saved client credentials
if gauth.credentials is None:
gauth.LocalWebserverAuth() # Authenticate if they're not there
elif gauth.access_token_expired:
gauth.Refresh() # Refresh them if expired
else:
gauth.Authorize() # Initialize the saved creds
gauth.SaveCredentialsFile("mycreds.txt") # Save the current credentials to a file
drive = GoogleDrive(gauth)
## Collect Saved Translations files from Drive and save file
fileList = drive.ListFile({'q': "'root' in parents and trashed=false"}).GetList()
jsonList = []
for file in fileList:
if file['title'] == 'Saved translations':
print('Found Saved Translation File -- ID: %s, Date Created %s' % (file['id'], file['createdDate']))
jsonList.append({'id': file['id'], 'date': file['createdDate']})
if len(jsonList) < 1:
sys.exit('No saved translation files')
jsonList = sorted(jsonList, key=lambda x: x['date'], reverse = True)
fileId = jsonList[0]['id']
_file = drive.CreateFile({'id': fileId})
_file.GetContentFile(export_path+'translations.xlsx',
mimetype = 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet')
## Clean files and save Anki upload files
ogdf = pd.read_excel(export_path+'translations.xlsx', header = None)
ogdf.columns = ['from_lang', 'to_lang', 'from_trans', 'to_trans']
df = deepcopy(ogdf)
russiandf = df[(df['from_lang']=='Russian')|(df['to_lang']=='Russian')].copy()
if russian_stress:
print("Accessing Russiangram")
driver = webdriver.Chrome()
driver.get("http://russiangram.com/")
russiandf['from_trans'] = russiandf.apply(lambda x: get_stress_marks(x.from_trans, driver, rooglish) if x.from_lang == 'Russian' else x.from_trans, axis = 1)
russiandf['to_trans'] = russiandf.apply(lambda x: get_stress_marks(x.to_trans, driver, rooglish) if x.to_lang == 'Russian' else x.to_trans, axis = 1)
df = clean_df(df)
russiandf = clean_df(russiandf)
all_langs = set(df.from_lang.values).union(set(df.to_lang.values))
all_langs.remove('English')
for lang in all_langs:
if lang == 'Russian':
exportdf = russiandf
if lang == 'Polish':
exportdf = df[((df['from_lang']==lang)|(df['to_lang']==lang))&(df['from_lang']!='Russian')&(df['to_lang']!='Russian')]
exportdf[['from_trans', 'to_trans']].to_csv(export_path+lang+'_anki_import.csv',
index = False,
header = None,
encoding="utf-8-sig")
finaldf = pd.concat([df, russiandf])
finaldf.to_csv(export_path + "clean_translations.csv", index = False, encoding="utf-8-sig")
## Upload to Drive and delete all Saved Translation files
upload = drive.CreateFile({'title': 'clean_translations.csv'})
upload.SetContentFile(export_path + "clean_translations.csv")
upload.Upload()
print('Successfully uploaded clean file with ID {}'.format(upload.get('id')))
for file in jsonList:
removeFile = drive.CreateFile({'id': file['id']})
removeFile.Delete()
if __name__ == "__main__":
create_anki_uploads()The result of the script is that it outputs clean csvs to the specified location, as seen here:

4) Creating the Flashcards in Anki
Finally, I navigate to my language decks in Anki. I then click “file -> import”, and I read in the prepared csv files. Voila!

Conclusion
I hope this helps someone create their own system. If you have a way to improve this approach to learning vocabulary, please let me know.
Of course, procedures are not everything. The best way to learn a language is to speak with someone. Language learning is more about creativity and improvisation than it is about rote memorization. In language and in life, we should embrace change and improvisation together with the steady rigor of incremental improvement.
As a reminder of this important duality, here is a Byzantine image of Mnemosyne, the Greek goddess of memory, and of Hermes, the Greek god of language, trade and travel:
Mnemosyne 
Hermes 